Availability Archetype in Practice
Today I want to write about availability software archetype. This will be not a generic description of it but rather a case study of problem I had to solve.
So without further ado: How I designed a flexible availability system that scales to 100k+ resources.
First Problem
So let’s start with business requirements. We want to build a platform where we want to connect clients with service providers. Important fact is that we book somebody to provide those services for a given period of time.
Lets call those two parties clients and providers.
Providers should be able to define the default availability on a week basis**.** It’s like their working hours. In example: “By default I’m available on Mondays from 9am to 5pm and Fridays from 9am to 3pm.”
Providers should be able to define the availability overwrite on a date basis. In example: “I’m working from 9am to 5pm on Mondays but next Monday (i.e. 23.06.2025) I will work only till 12am). “
Providers can also define things like:
- Days off. i.e. if they go on holidays.
- Buffer time - minimum buffer time between meetings.
- Booking upfront limit - somebody don’t want to be booked for the next 3 months. That’s why his limit might be 2months.
- Does my 3rd party calendar has impact on my availability? Each provider can set if his 3rd party calendar has impact on his availability. i.e events from google calendar.
Also if client is creating the booking with provider, lock is valid for 5min if not confirmed. So client must confirm the booking within 5min. In the meantime, provider is reserved for him.
Ok lets stop here. It’s a lot of rules but all of those are required to answer only two questions.
- Is given provider available at date __ from __ to __ ?
- Who is available at date __ from __ to __ ?
That means we are dealing with Availability Archetype.
One more problems
Most of the resources I found about this archetype talk about the locks on the resource and the reason of the lock. But in this case we can’t say beeing not locked == beeing available.
There is a few more problems. We can’t use Python datetime across the whole system. Datetime is a point in time concept. But “on Mondays at 13:00” is not exactly point in time.
That means we are dealing here with two concepts.
- Weekday + time range. i.e. Wednesdays from 9am to 5am.
- Date + time range. i.e. 23.06.2025 from 9am to 5am.
First one can be used to define the default availability. This is simple, assuming you work 9-5 from Monday to Friday you will have 5 records for default availability.
Second one is much more useful. We can say, for a specific date in given time range, I’m available/not available (lock) Bum! We have locks and availability overwrite defined.
Lets sum up it with example class.
@dataclass
class AvailabilitySlot:
class SlotType(StrEnum):
DEFAULT = "default"
OVERWRITE = "overwrite"
LOCK = "lock"
class LockType(StrEnum):
DAY_OFF = "day_off"
BOOKING = "booking"
GOOGLE_CALENDAR = "google_calendar"
resource_id: str
week_day: int | None # for default slots and locks for day off.
date: date | None # for overwrite slots and locks
start_time: time
end_time: time
slot_type: SlotType
lock_type: LockType | None
Fun Part begins
Actually at this point we can say we have more or less shape of the db.
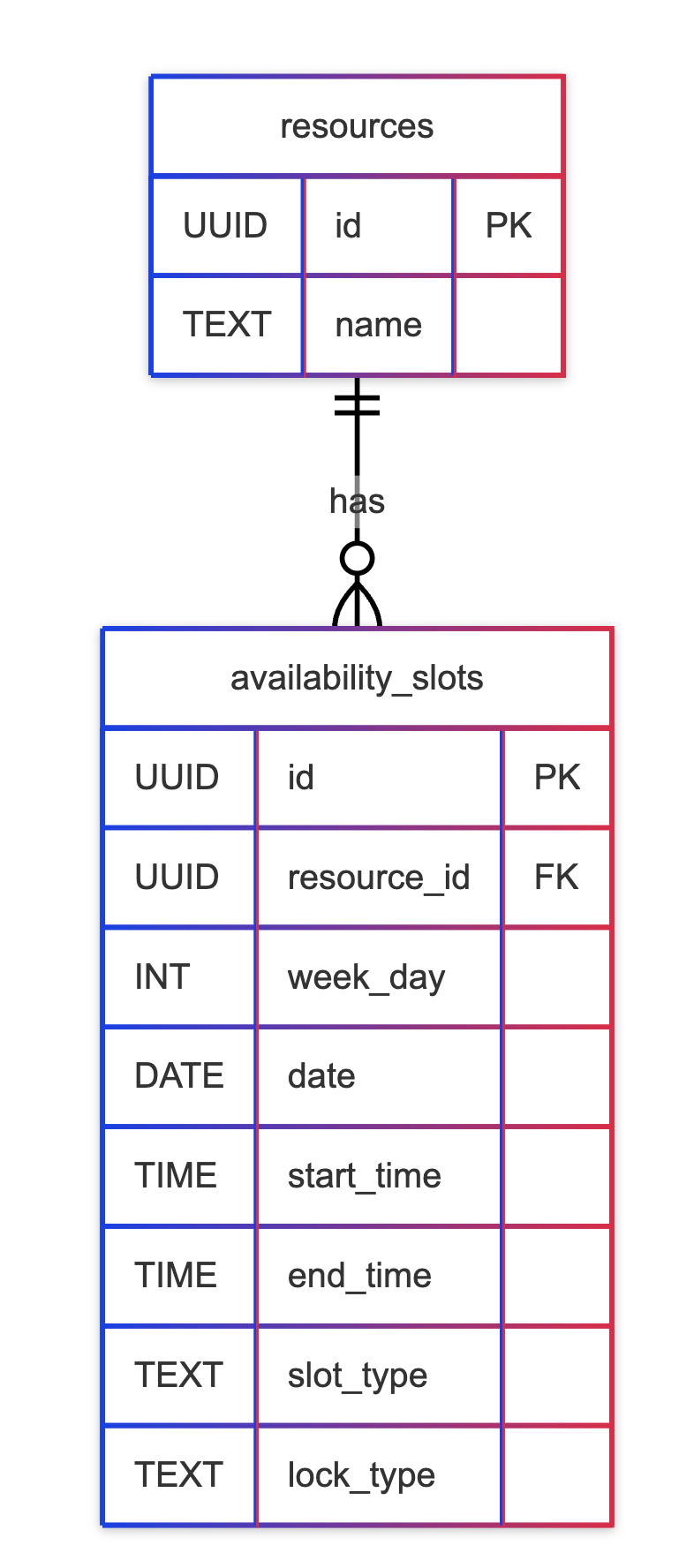
So we can easily for a specific resource, fetch related availability slots and compute the rest of the logic we will talk about a bit later. At this point we can add one assumption about this model. We are asking for a future availability. Ofc. it’s also easy to compute the availability in the past but for a query optimisation we can only fetch the slots from the future.
Is given Provider available at __
Lets introduce some code into this problem. Everything will be available in this repo at the end.
https://github.com/JakubSzwajka/availability-archetype
What we are aiming for is a flexible model that can handle many different scenarios we were talking about. Most of them are about Resource. So lets start with something that we can ask “are you available at __ ?”, something that we can put some lock on, and also that we can unlock! And last but not least, something that we can define the availability for!
class Resource:
def __init__(self, id: str, name: str, buffer_minutes: int = 0, booking_upfront_days: int = 90):
self.id = id
self.name = name
self.__buffer_minutes = buffer_minutes
self.__booking_upfront_days = booking_upfront_days
self.__default_availability: dict[int, TimeSlotSet] = {}
self.__overwrites: dict[date, TimeSlotSet] = {}
self.__locks: dict[date, TimeSlotSet] = {}
def is_available(self, slot: DateSlot) -> bool:
if slot.date < date.today() + timedelta(days=1) or slot.date > date.today() + timedelta(days=self.__booking_upfront_days):
return False
week_day = slot.date.weekday()
available_by_default = self.__default_availability.get(week_day, TimeSlotSet()).includes(slot)
has_overwrite_for_that_date = slot.date in self.__overwrites
available_by_overwrite = self.__overwrites.get(slot.date, TimeSlotSet()).includes(slot)
locked = False
if self.__buffer_minutes == 0:
locked = self.__locks.get(slot.date, TimeSlotSet()).overlaps(slot)
else:
locks = self.__locks.get(slot.date, TimeSlotSet())
for l in locks.slots:
extended = l.extend(Time(0, self.__buffer_minutes))
if extended.overlaps(slot):
locked = True
break
return (available_by_default if not has_overwrite_for_that_date else available_by_overwrite) and not locked
def lock(self, slot: DateSlot) -> None:
if slot.date not in self.__locks:
self.__locks[slot.date] = TimeSlotSet()
self.__locks[slot.date].add(slot)
def unlock(self, slot: DateSlot) -> None:
if slot.date in self.__locks:
self.__locks[slot.date].remove(slot)
if not self.__locks[slot.date].slots:
# clean up empty lock set
del self.__locks[slot.date]
def set_default_availability(self, week_availability: dict[int, TimeSlotSet]) -> None:
self.__default_availability = week_availability
def set_overwrite_availability(self, date: date, slots: TimeSlotSet) -> None:
self.__overwrites[date] = slotsLets analyse this class. Fetched from db with relevant slots we can easily access default availability, its overwrite and other rules. is_available becomes the single point that can answer our question.
By using lock and unlock we can easily add specific locks (also we can add type of the lock later) that will have direct impact on result of is_available.
The same for set_default_availability and set_overwrite_availablity.
Please note that Resource is supported by other classes like TimeSlotSet, TimeSlot, DateTimeSlot, WeekDayTimeSlot and Time. I don’t want to throw the whole implementation of:
- merging the time ranges,
- adding new time range to set of time ranges,
- ⚠️ operations on
Time. Some operations might exceed 24h. Single time range might become two distinct time ranges to cover two days. No matter if they are weekdays or two dates.
Please visit repo for details. https://github.com/JakubSzwajka/availability-archetype
Add some fantasy ✨
The whole point of this implementation is to have model flexible enough that introducing new business requirements is easy. So let’s create a new requirement and verify that we can support them.
Provider can set max working hours per day. Lets say provider is available for 10hours a day but at most he would like to work 7. No more. ****
Looking at is_available method this seems like still easy to implement. Just introduce new property on a resource level like self.__max_working_hours_per_day and check if the sum of locks per day we want to book does not exceed this.
Got any other ideas that we can check? Feel free to drop a message/comment.
Which resources are available at __ ?
Now lets try to answer the second question about the list of resources. This will be the harder one and I think there is a few approaches we can do.
First, the most naive one is to fetch all the resources and filter those where is_available returns True. This already seems like a bad idea but lets do it so we can compare it later.
Lets add real database and ResourceRepository. We will use postgres and SQLAlchemy.
from enum import StrEnum
from datetime import date as date_type, time
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column, relationship
from sqlalchemy import String, DateTime, Integer, ForeignKey, Date, Time as SQLTime, Index
from uuid import uuid4
from datetime import datetime, UTC
class Base(DeclarativeBase):
id: Mapped[str] = mapped_column(String, primary_key=True, default=lambda: str(uuid4()))
created_at: Mapped[datetime] = mapped_column(DateTime(timezone=True), default=lambda: datetime.now(UTC))
updated_at: Mapped[datetime] = mapped_column(
DateTime(timezone=True), default=lambda: datetime.now(UTC), onupdate=lambda: datetime.now(UTC)
)
class ResourceModel(Base):
__tablename__ = "resources"
name: Mapped[str] = mapped_column(String, nullable=False)
buffer_minutes: Mapped[int] = mapped_column(Integer, nullable=False)
booking_upfront_days: Mapped[int] = mapped_column(Integer, nullable=False)
availability_slots: Mapped[list["AvailabilitySlotModel"]] = relationship(back_populates="resource")
class AvailabilitySlotModel(Base):
__tablename__ = "resource_availability_slots"
__table_args__ = (
Index("ix_slot_resource", "resource_id"),
)
class SlotType(StrEnum):
DEFAULT = "default"
OVERWRITE = "overwrite"
LOCK = "lock"
class LockType(StrEnum):
DAY_OFF = "day_off"
BOOKING = "booking"
GOOGLE_CALENDAR = "google_calendar"
resource_id: Mapped[str] = mapped_column(String, ForeignKey("resources.id"), nullable=False)
resource: Mapped[ResourceModel] = relationship(back_populates="availability_slots")
week_day: Mapped[int] = mapped_column(Integer, nullable=True)
date: Mapped[date_type] = mapped_column(Date, nullable=True)
start_time: Mapped[time] = mapped_column(SQLTime, nullable=False)
end_time: Mapped[time] = mapped_column(SQLTime, nullable=False)
slot_type: Mapped[SlotType] = mapped_column(String, nullable=False)
lock_type: Mapped[LockType] = mapped_column(String, nullable=True)
lock_by_id: Mapped[str] = mapped_column(String, nullable=True)Naive approach
class ResourceFacade:
def __init__(self, resource_repo: ResourceRepo):
self.resource_repo = resource_repo
def get_available_at(self, slot: DateTimeSlot, session: Session) -> list[Resource]:
resource = self.resource_repo.get_all(session)
return [r for r in resource if r.is_available(slot)]
class ResourceRepo:
def get_all(self, session: Session) -> list[Resource]:
with session.begin():
query = session.query(ResourceModel)
resource_rows = query.all()
return [self._to_domain(row) for row in resource_rows]| Approach | Resources count | Average query time over 50 runs |
|---|---|---|
| Naive | 1000 | 2.6537 s (min 2.5248, max 2.9855) |
As you see.. it is what it is. It’s unacceptable. And this is without http working on 48GB M4 Mac.
Narrow down the search
What we want to avoid is to move this big business logic on the db level. I think its hard to maintain and test it this way. So lets try to narrow down what we are fetching from db, only to those that are potentially available at given moment.
Also with this filter we don’t need to load everything into memory which takes most of the time.
First statement now asks Postgres for only the distinct resource_id values that satisfy the filter. Second statement uses that ID list with selectinload() to pull just those resources + their slots.
Also note the with_loader_criteria. For resources that match our filter, we load only slots that match also the same filter. That means we load only the stuff we need to answer our questions.
class ResourceRepo:
def get_all(self, session: Session, available_at: date) -> list[Resource]:
week_day = available_at.weekday()
slot_alias = AvailabilitySlotModel
id_subq = (
select(ResourceModel.id)
.join(slot_alias, slot_alias.resource_id == ResourceModel.id)
.filter(
or_(
and_(
slot_alias.slot_type == AvailabilitySlotModel.SlotType.DEFAULT,
slot_alias.week_day == week_day,
),
and_(
slot_alias.slot_type.in_(
[
AvailabilitySlotModel.SlotType.OVERWRITE,
AvailabilitySlotModel.SlotType.LOCK,
]
),
slot_alias.date == available_at,
),
)
)
.distinct()
).subquery()
slot_filter = or_(
and_(
AvailabilitySlotModel.slot_type == AvailabilitySlotModel.SlotType.DEFAULT,
AvailabilitySlotModel.week_day == week_day,
),
and_(
AvailabilitySlotModel.slot_type.in_(
[
AvailabilitySlotModel.SlotType.OVERWRITE,
AvailabilitySlotModel.SlotType.LOCK,
]
),
AvailabilitySlotModel.date == available_at,
),
)
resource_rows = (
session.query(ResourceModel)
.filter(ResourceModel.id.in_(select(id_subq.c.id)))
.options(
selectinload(ResourceModel.availability_slots),
with_loader_criteria(AvailabilitySlotModel, slot_filter, include_aliases=True),
)
.all()
)
return [self._to_domain(row) for row in resource_rows]| Approach | Resources count | Average query time over 50 runs |
|---|---|---|
| Naive | 1 000 | 2.6537 s (min 2.5248, max 2.9855) |
| Narrowing to potential available at given date | 10 000 | 0.7663 s (min 0.7056, max 1.2136) |
| Narrowing to potential available at given date + two queries | 100 000 | 8.7517 s (min 8.0404, max 10.0868) |
That makes difference but we are not there yet!
Narrow down even more!
In the previous example we’ve narrow down only on a date level. lets do the same on the time level.
NOTE: its important to have everything stored and query in the same timezone. Just use UTC.
def get_all(self, session: Session, slot: DateTimeSlot) -> list[Resource]:
week_day = slot.date.weekday()
slot_alias = AvailabilitySlotModel
filter = or_(
and_(
slot_alias.slot_type == AvailabilitySlotModel.SlotType.DEFAULT,
slot_alias.week_day == week_day,
slot_alias.start_time <= slot.start_time.time(),
slot_alias.end_time >= slot.end_time.time(),
),
and_(
slot_alias.slot_type.in_(
[
AvailabilitySlotModel.SlotType.OVERWRITE,
AvailabilitySlotModel.SlotType.LOCK,
]
),
slot_alias.date == slot.date,
slot_alias.start_time <= slot.start_time.time(),
slot_alias.end_time >= slot.end_time.time(),
),
)
id_subq = (
select(ResourceModel.id)
.join(slot_alias, slot_alias.resource_id == ResourceModel.id)
.filter(filter)
.distinct()
).subquery()
resource_rows = (
session.query(ResourceModel)
.filter(ResourceModel.id.in_(select(id_subq.c.id)))
.options(
selectinload(ResourceModel.availability_slots),
with_loader_criteria(AvailabilitySlotModel, filter, include_aliases=True),
)
.all()
)
return [self._to_domain(row) for row in resource_rows]
We are getting there! For 10k resources and over 2M of slots we have average query time over 50 runs: 0.3545 s (min 0.3228, max 0.4478)
Biggest gain. UX
All of this was tested when checking all possible resources in the db. But lets consider some kind of the frontend browser for this. The question is: if I want to find a Provider (Resource), do I care availability of all possible results or do I care about first 10? 50? 100? What about pagination?
Lets just do the same but for first 50 results. To increase the challenge I will test it on 100k resources and 20 700 000 slots.
def get_all_for_slot(self, session: Session, slot: DateTimeSlot, limit: int, offset: int) -> list[Resource]:
week_day = slot.date.weekday()
slot_alias = AvailabilitySlotModel
filter = or_(
and_(
slot_alias.slot_type == AvailabilitySlotModel.SlotType.DEFAULT,
slot_alias.week_day == week_day,
slot_alias.start_time <= slot.start_time.time(),
slot_alias.end_time >= slot.end_time.time(),
),
and_(
slot_alias.slot_type.in_(
[
AvailabilitySlotModel.SlotType.OVERWRITE,
AvailabilitySlotModel.SlotType.LOCK,
]
),
slot_alias.date == slot.date,
slot_alias.start_time <= slot.start_time.time(),
slot_alias.end_time >= slot.end_time.time(),
),
)
id_subq = (
select(ResourceModel.id)
.join(slot_alias, slot_alias.resource_id == ResourceModel.id)
.filter(filter)
.distinct()
.limit(limit)
.offset(offset)
).subquery()
resource_rows = (
session.query(ResourceModel)
.filter(ResourceModel.id.in_(select(id_subq.c.id)))
.options(
selectinload(ResourceModel.availability_slots),
with_loader_criteria(AvailabilitySlotModel, filter, include_aliases=True),
)
.all()
)
return [self._to_domain(row) for row in resource_rows]Average query time over 50 runs: 0.4787 s (min 0.4631, max 0.5957)
I will take this! ✅
Lessons learned
Lets split the whole query in 2 parts.
- SQL level
- Python (Domain + Application)
At this point, if we want to add more business rules we will put them in part 2. It’s where we actually check if the business rules are satisfied.
Lets compare how long we spend in each one for 100 000 resources.
- SQL ~ less then 500ms
- Python ~0.5ms
That means we have a model that quite resistant to changing business logic cuz we already fetch most of the data so there is basically no risk that if we implement max working hours per day it will kill the performance.
Back to the beginning. We are here for Availability Archetype. The whole point was to show that having proper abstraction over business problems, we can achieve easy and flexible system. Treat the whole codebase as a part of something bigger. Right now, you can add any module that will just create a lock, for whatever reason, sync or async and make resource unavailable. That means querying for availability stays the same.
Your Turn
💡Are you dealing with complex availability requirements in your system? If you’re architecting similar systems, I’d love to hear about your approach to balancing performance with business rule flexibility.”